

OCR图文识别是否能够保留原始格式?
发布时间:20231023 来源:极光PDF 作者:牛叔

众所周知,OCR技术能够提取文字,但它是否能够保留原始文档的格式和排版,使得提取出的文本保持与原始文档一致的外观?在本文中,我们将探讨OCR技术的能力与局限性,以及如何有效地保留原始文档的格式。通过深入了解OCR技术的挑战和解决方案,我们将引入一款专业的PDF编辑软件——极光PDF编辑器,探讨它如何在OCR图文识别过程中发挥重要作用。
一、OCR技术的基本原理
OCR技术的基本原理是将扫描的图像中的文字识别出来,然后将其转化为可编辑的文本格式。这个过程包括以下几个步骤:
● 图像采集:扫描仪或相机将文档转化为数字图像。这个图像可能包含文本、图像和其他元素。
● 文本识别:OCR软件会对图像进行分析,尝试识别其中的文字。这是一个复杂的过程,因为文字可能以不同的字体、大小和颜色出现,甚至可能存在一些扭曲或模糊。
● 文字转换:一旦文字被识别出来,OCR软件会将其转化为计算机可理解的文本数据。这通常包括将文字编码成Unicode字符。
● 文本编辑:用户可以编辑和格式化识别出的文本,以满足其需求。这通常需要一个文本编辑工具,比如Microsoft Word。

二、OCR的能力和局限性
OCR技术在文字识别方面取得了显著的进步,但它并不是完美的。以下是一些OCR技术的能力和局限性:
1、OCR的能力
● 高准确性:现代OCR软件通常能够以高准确性识别印刷文字,甚至包括一些手写文字。
● 多语言支持:许多OCR软件支持多种语言,使其适用于全球范围内的文档。
● 多格式输出:OCR软件通常能够将识别出的文本输出为不同格式,如TXT、Word、PDF等,以满足用户的需求。
2、OCR的局限性
● 图像质量影响:OCR的准确性受到输入图像的质量影响。如果图像模糊、扭曲或包含噪音,识别准确性可能会下降。
● 格式保留:OCR技术通常难以保留原始文档的格式、排版和图像元素。这意味着识别出的文本可能会丧失原始文档的外观。
● 手写文字识别:虽然OCR技术在印刷文字方面表现出色,但对手写文字的识别仍然存在挑战。
三、保留原始格式的挑战
一个关键问题是如何在OCR过程中保留原始文档的格式。原始格式通常包括字体、字号、排版、颜色、图像等元素。OCR软件的主要任务是提取文本,而不是保留这些元素。因此,原始格式的保留通常需要额外的努力。
● 字体和字号:OCR软件通常不会识别文本的具体字体和字号。这意味着提取的文本将以默认字体和字号呈现,而不是与原始文档一致。
● 排版和布局:维护原始文档的排版和布局是一个复杂的任务。OCR软件通常将文本按照阅读顺序排列,而不是保留原始文档的页面布局。
● 图像和图表:OCR软件通常无法识别和保留原始文档中的图像和图表。这些元素通常会丢失。
● 颜色和样式:原始文档中的文本颜色和样式也难以被OCR软件识别和保留。
四、如何保留原始格式
尽管OCR技术在原始格式保留方面存在挑战,但仍有一些方法可以帮助改善这一问题:
● 手动校对:一种方法是手动校对OCR输出,以修复格式和排版错误。这需要额外的时间和努力,但可以提高文档的质量。
● 专业OCR工具:一些专业OCR工具提供更多的格式保留选项。它们可能允许用户指定字体、字号和排版,以更好地匹配原始文档。
● PDF编辑软件:使用PDF编辑软件可以在某种程度上维护文档格式。例如,极光PDF编辑器是一款客户端类型的PDF编辑软件,它支持文字和图像提取以及编辑操作。用户可以使用它来打开PDF文档,提取文字,并进行一定程度的格式编辑。
五、推荐PDF编辑软件:极光PDF编辑器
在解决OCR保留原始格式的问题上,专业的PDF编辑软件发挥着关键作用。极光PDF编辑器是一款功能强大的PDF编辑工具,它不仅支持文字和图像提取,还能够在一定程度上维护文档的格式和布局。
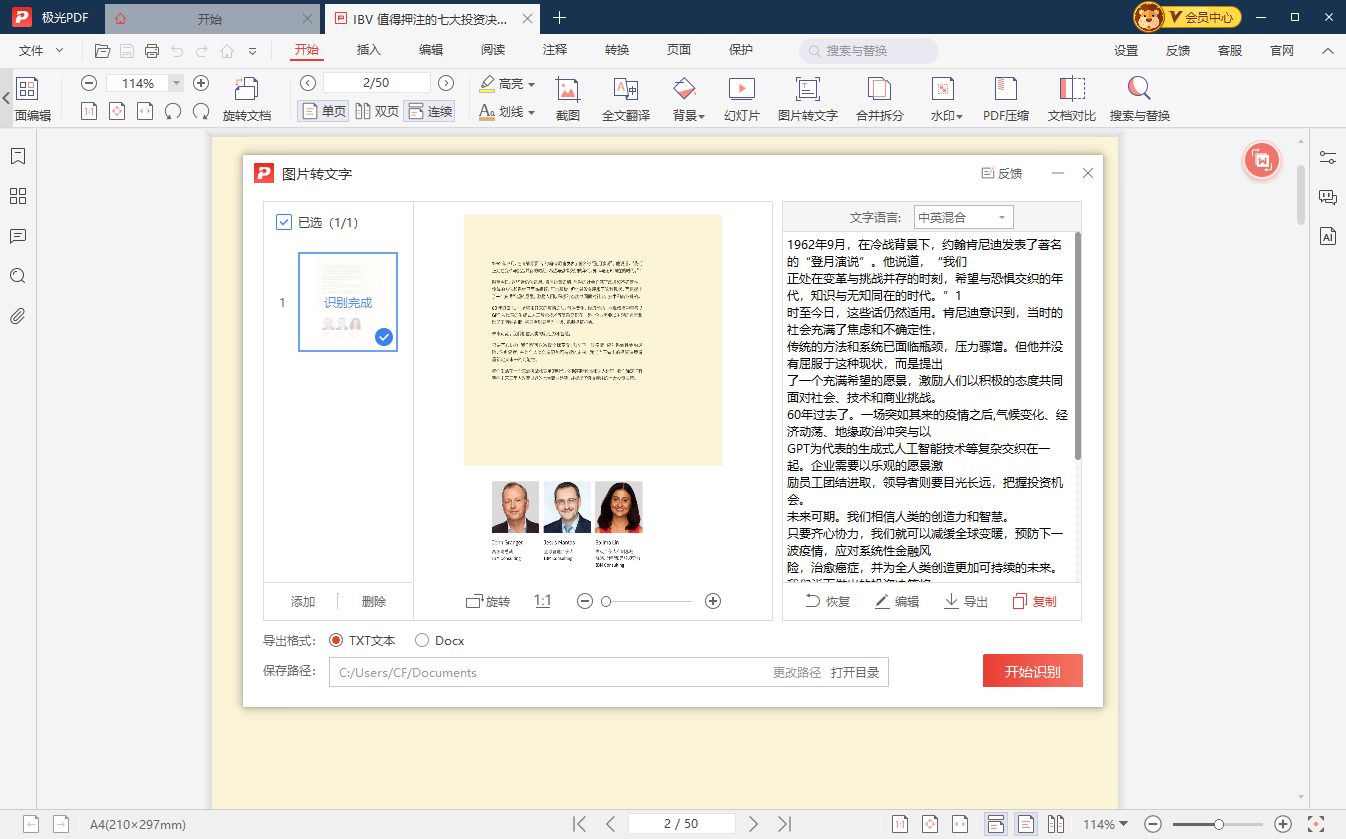
使用极光PDF编辑器提取文字的步骤如下:
● 打开PDF文档:在PDF软件中打开要提取文字的PDF文档。
● 选择要提取的文字:点击文档中要提取文字的位置。
● 提取图片文字:在右侧菜单选择“提取图片文字”。
● 开始识别:弹出文字识别弹窗后,点击右下方“开始识别”按钮。
● 导出为可编辑格式:识别出的文字结果可以复制或导出为可编辑格式,如TXT、Word等。
综上所述,OCR图文识别在数字化时代扮演着重要角色,使得文档处理更加高效。然而,保留原始格式仍然是一个挑战,特别是对于需要维护文档外观和排版的用户。在这方面,选择合适的PDF编辑软件,如极光PDF编辑器,可以帮助用户在OCR过程中更好地保留原始格式,提高文档质量和可编辑性。

更多动态请关注微信公众号,请使用微信“扫一扫”

